







 A Framework for Generating Numerical Test Data
A Framework for Generating Numerical Test DataWhile attempting to bring the benefits of early unit testing to a highly numerical application, we found a need to generate large quantities of test data using several independent variables. We found the obvious approach using nested loops unsatisfactory. An alternative was developed using chained objects to represent the independent variables, with minimal repetition of either code or structure.
The work described here was part of the development of a highly numerical component within a subsystem of a large (>$200M) defence system project. The component uses Kalman filters [Welch-] to assist in target tracking. The Kalman filter algorithm is a method for reducing noise on measured data, and also allows for interpolation and extrapolation of measurements. The component also does a considerable amount of other processing related to the tracking loop. Not surprisingly for a project of this size, the main project management processes are rooted in high-ceremony, document-centric methods. The data processing subsystem was developed in Ada, using the Rational Unified Process. The development environment used ColdFrame [coldframe] to generation the framework from UML, and encouraged early unit testing using the AUnit unit test framework, an Ada version of the well known xUnit family [aunit].
We developed this component with a view to using as agile a process as possible within the constraints of the overall project policies. In particular, we wanted to explore the claimed benefits of early testing methodologies such as Test Driven Design, although automatic code generation was used for the structural framework of the component. To reconcile the two, we used a test-first strategy to implement the method bodies within the generated framework. Some parts of the component contain a great deal of numerical code, which poses challenges for this style of testing; there may be many input combinations that need to be tested to give confidence that the function's implementation will perform correctly across the entire input domain. For testing those parts, the following procedure was adopted:
-
One engineer implemented the function in C++.
-
This implementation was used to generate a file containing inputs and outputs for the function, covering as many odd cases as possible (maximum and minimum values, zeroes and angles such as p/2).
-
Another engineer implemented an AUnit test harness that uses this data.
-
The second engineer implemented the function in production code, directly from the specification without reference to the initial implementation.
-
If the two implementations do not agree within suitable tolerances, allowing for rounding errors, there is most likely a bug in at least one of the implementations. We then entered a debugging phase, as far as possible retaining the independence of the two implementations.
While this procedure does not completely guarantee the correctness of the code, it does provide a valuable check, and a regression test to prove that nothing changes later. The highly numerical code was also Fagan inspected to further add confidence. We see the two approaches as complementary; both approaches found some defects in code that had been through the other.
The original test data generators used a simple structure of nested for loops. An example is shown in Listing 1, which creates solutions of quadratic equations using the well known formula. This is of course not a real example; the real algorithms that were being tested are not available for publication. While the nested loops were easy to implement at first, this approach suffered from a number of drawbacks:
-
Indentation quickly used up screen space, reducing readability.
-
It was necessary to ensure manually that header and data columns match up in the output file, which introduced duplication of structure.
-
Code to show progress was repeated by copy and paste throughout the numerous dataset generators, which is clearly duplication of code.
-
Housekeeping (managing the loops and files) and performing the calculation were not separated.
-
Amongst other faults, this design is therefore breaking two well-known principles in good software: separation of concerns, and avoiding duplication.
A more elegant design was indicated, one which would:
-
Remove duplication, both of code and of structure.
-
Automate as much as possible, including progress reporting.
-
Separate management of the loops from the business of calculating the test values;.
-
Support linear and logarithmic iterations.
-
While being minimally intrusive in the implementation of the equations being tested.
The problem of iterating several functions with the same values could easily be solved by providing the iteration as an algorithm, and passing it the function to be called with the iterated values. An example of this is shown in Listing 2. It would clearly be straightforward to extend this to variable limits and steps by passing in {step, min, max} tuples for each variable. It seems intuitive that this could be extended to arbitrary numbers of iterated values, and probably logarithmic iterations, using template meta-programming techniques. However, despite some considerable head-scratching I could not find a suitable solution along this route. This is not to say that such a solution does not exist, but an easier alternative was found first.
Being a "classic" C++ programmer at heart, it seemed natural to look for an object based solution, using some kind of object to represent iteration over a range of values, and for these to be chained together to create the nesting by functional recursion. The problem was that the values of all the iterated variables have to be available to the final function that will create the output values.
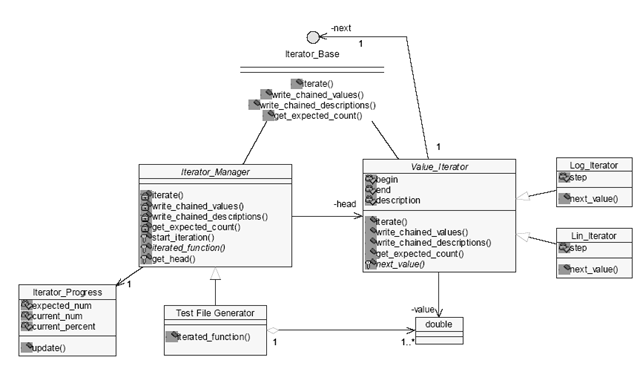
The first successful form of the framework used objects of a Value_Iterator class as members of the client class to do the iteration, with operator double() to access the values. The name Iterator may not have been the best choice, as it perhaps implies too strongly the iterators of the standard library collections. However, it does iterate over the input values for the test. Value_Iterator is derived from the Iterator_Base interface, which defines the methods needed to take part in the recursion. The client of the framework is a class derived from an abstract base, Iterator_Manager, which encapsulates common behaviour for managing the recursion. Two concrete Value_Iterator classes are declared apart from the manager, to provide linear or logarithmic steps. The framework is shown in the UML diagram figure 1, and an example of its usage is shown in Listing 3.

The Iterator_Manager is responsible for managing a chain of Value_Iterator objects, although the objects themselves are members of its client specialisation, here Test_File_Generator. It provides some functions for management, but it is still abstract, as it requires the client class to define the iterated function and the head of the chain. Its start_iteration method is responsible for doing the iteration, by calling the iterate method on the head of the chain, and doing any necessary preparation and cleanup. It implements the Iterator_Base methods to terminate the iteration; its iterate method calls the final iterated function, and its other Iterator_Base methods return straight away. It is therefore responsible for both the head and tail of the chain of iterators, the head being provided by Iterator_Manager::get_head, and the tail being its Iterator_Base part.
The Test_File_Generator class is the client of the framework in this example. It is responsible for implementing the final function that uses the iterated values, and writing the input and output values to file. It writes the input values by calling write_chained_values on the iterator returned by the base class get_head method.
The Value_Iterator is responsible for doing the looping and the recursion. Its iterate method runs its loop from begin to end, relying on its specialisations to provide the next value, given the current value. This allows specialisations for linear or logarithmic steps, or potentially for some other sequencing method not yet thought of. Within that loop it calls the iterate method on its next member. Its write_chained_values method recurses to the next iterator in the chain, and then writes its own value to the file.
The Iterator_Progress class, which is omitted from the listings for brevity, prints a "% complete" message to the console using the expected total number of steps. It calculates the expected number of steps at the start by calling get_expected_count on the head iterator, which multiplies each iterator's own number of loops by the next iterator's total number of loops, recursively.
This approach was reasonably satisfactory, but had some drawbacks:
-
It was necessary to duplicate the names of the variables: the iterators are named once in the declaration of the client class, and once in the definition of its constructor.
-
This decision of linear or logarithmic type of iterator is separated from the definition of its step and limits, although these are clearly related.
-
The iterators have to be chained together manually in the constructor, introducing a third place where the iterator is named.
Listing 3 shows an example of usage of this approach. The implementation is not shown as it adds little to the discussion.
Most of the drawbacks in the Iterator method derive from the duality of the Iterator object, as both the iterator and the value being iterated. This leads to the object being known to both the framework's Iterator_Manager class and its derived client class, as shown by the derived association[1] from Iterator_Manager to value_Iterator in Figure 1. A clearer separation of concerns was found by binding the Iterator objects to members of an enclosing class. This leads to the class model shown in Figure 2. Note that the derived association has been replaced by two distinct associations, each with its own clear purpose.
Listing 4 is the code for the header file of the framework, with the implementation in Listing 5. Assertions, error handling and private/protected constructors/destructors are omitted for brevity. Note the use of the C library FILE I/O mechanism; we found that this was significantly faster than iostream on the implementation used, and performance is fairly important here. A "gold plated" solution might use a policy or helper class to parameterise the choice of output library, but that was not necessary in this project.
Listing 6 gives a code listing for an example usage of the framework. The client creates instances of Value_Iterator in its constructor, chaining them together as it does so, and binding them to its own member variables. Thus when the iterate method on the head iterator finally ends up calling the iterated_function method on the client, its data members hold the current values for this step and can be used without further ado.
By making the iterator objects themselves anonymous, it becomes possible to declare the type of the iterator and initialise the step values on the same line, which makes the connection between log iterator and log steps clearer. It also means that the iterators can be chained by chaining the constructors, rather than by naming them again. In the previous example, adding a new iterator meant having to change the argument to another iterator's constructor, which was a small but noticeable hassle in maintenance.
In the original example progress was indicated by printing a chain of dots, with no indication of how many to expect. When the loops were coded in place in each generator, calculating how many to expect would have required repeating the loop parameters. Extracting the increments into the iterators enables the get_expected_count method to do a "dry run", which means a useful progress indicator can be provided without this repetition.
The framework fails to meet the objectives in two points Firstly, the variable name must be duplicated in the constructor of the Iterator object in order to make the binding. While this does seem to be an improvement over repeating the object name twice in the constructor list, it is still less than satisfactory . Secondly, the output column headings written in the generator's start method are still separated from the output of the column data in iterated_function. There is therefore a maintenance risk that the column heading could get out of step. No way around this was found that did not result in unjustifiable complexity elsewhere. However, by removing most of the management code, the two relevant lines are now much closer together than in the naïve solution, so the risk is at least to some extent mitigated. An additional minor drawback in this version is that binding the iterator object to a member variable could be seen as breaking the encapsulation of the classes.
Presently the bound member variables must be doubles, which was sufficient for our needs. It would be straightforward to parameterise the Iterator class on the type of bound variable.
The final version meets most of the drivers listed in the introduction:
-
It avoids unnecessary complexity and advanced techniques;
-
It supports linear and logarithmic steps and progress reporting;
-
Most of the duplication is avoided as the iterator objects do not need to be declared in the class.
This framework provides a simple way of producing deep nested loops, with readable client code, clear separation of concerns between client and framework classes, and improved progress reporting. It meets most of the design objectives in a natural, "classic" C++ style, without resort to possibly obscure C++ techniques. This solution is simpler than was expected at the start of the work, which is pleasing.
The author wishes to thank the reviewers for their helpful comments, particularly Alan Griffiths for the basis for listing 2.
Only a couple of issues ago I was writing about the variety of C++ dialects in use. This article illustrates this: after the author tried using some ideas from "Modern C++ Design" he was inspired to show that "Classic C++" also solves problems. However, some members of the Overload team feel that "Modern C++" offers a better solution. - ed.[Welch-] Greg Welch & Gary Bishop, An Introduction to the Kalman Filter, TR 95-041, University of North Carolina Chapel Hill, http://www.cs.unc.edu/~welch/kalman/kalmanIntro.html
[coldframe] ColdFrame project home page: http://coldframe.sourceforge.net
[1] In UML, a / in front of a role name or attribute indicates that it can be derived from something else on the model.
Overload Journal #69 - Oct 2005 + Programming Topics
| Browse in : |
All
> Journals
> Overload
> 69
(6)
All > Topics > Programming (877) Any of these categories - All of these categories |