







 Interface Versioning in C++
Interface Versioning in C++Having code that requires more than a single (binary) version of a shared library is what is commonly referred to as 'DLL Hell' in Windows. This can arise in a number of ways, but in particular, a new version of a component is released which must be consumed by clients of the previous version, as well as the new. Just as there are several reasons this might occur, there are varied methods of handling the problem, from the requirement for client code to handle unsightly conversions all the way through to down-right nasty and undefined, or at best, non-portable, behaviour. The approach described here attempts to find a best-of-all-worlds leading to reasonable client code and well-defined, portable implementation.
The problem
Consider a shared library1 which is used by multiple clients. Further, that the library is developed and maintained by a team (or company) that is different from those managing the clients. Any change to the library which causes the client code to recompile is a potential deployment nightmare. Release cycles need to be synchronised. Client teams need to co-ordinate the release of the shared library so that all interested clients either upgrade simultaneously, or else are quarantined to remain on the old version. In short, a lot of to-ing and fro-ing from all the parties involved.
The real problem is one of dependency management. If clients didn't need to recompile, there would be no problem with deploying the new version of the library, since (by definition) the client interface of the library must be unchanged. However, this would be an unacceptably onerous restriction on new library versions; the reality is that interfaces do grow stale from time to time, as new features are required.
The goal
This article explores how to add new methods to a class interface in such a way that client code need not recompile and redeploy if a new version of the library is released. Other changes to the library cannot be supported easily; deleting a method, or changing a signature (which is equivalent to adding a new method and removing the old one) aren't handled. It's possible to mark an old method as deprecated, allowing client code say one release cycle to change their code, but for the purposes of this article, a version upgrade means adding a new method to an existing type, or adding a new type.
This latter change is easily handled -clients running against a new version have no knowledge of the new type, and so cannot be dependent on it. This also applies to free-standing functions.2 The interesting case is adding a new method to a type already in use.
// part.h
#pragma once
namespace inventory
{
class part
{
public:
unsigned id() const;
private:
unsigned num;
};
}
|
| Listing 1 |
Consider the code in listing 1 (a concrete library). This code is intended to be part of a shared library called inventory. The client code is shown in listing 2.
// app.cpp
#include <part.h>
#include <iostream>
#include <memory>
// Also link to inventory.lib
int main()
{
using namespace std;
using namespace inventory;
unique_ptr< part > p( new part );
cout << p->id() << endl;
}
|
| Listing 2 |
As it stands, adding a new method to the part class would require the client application to recompile against the new header, relink with the new library and redeploy at the same time as the new library is released.
The goal is that when a new method is added to part, none of the above need to happen -the existing released client application will work against the new library version without changes.
Undefined behaviour is the result if the client doesn't recompile, but much worse than that is with most compilers, the undefined behaviour is that the program will still appear to work in this example. The reasons why are explored in 'False hope' (below).
But first things first.
Untying the knot
Any change to the library which requires the client to recompile also requires the client to redeploy. Briefly, the changes which might cause that are:
- Changes to the public member functions
- Changes to the base-class list.
- Changes to any protected or private member functions
- Changes to any data members (presumed to be private in any sane system).
For all except number 1, there is a simple solution: introduce a level of indirection. If the client code depended on a true interface type representing a part, instead of a concrete class, then any implementation details would be encapsulated by an implementing type, rather than the interface itself. If any base classes are required by the resulting interface type, then those must also be made into interfaces, because 'Abstractions should not depend upon details. Details should depend upon abstractions.' [Martin96].
In the example shown in listing 1, only the private data needs hiding.
// part.h
#pragma once
namespace inventory
{
class part
{
public:
virtual ~part();
virtual int id() const = 0;
};
part * create_part();
}
// part.cpp
#include "part.h"
namespace
{
class realpart : public inventory::part
{
public:
realpart();
int id() const;
private:
int num;
};
}
namespace inventory
{
part * create_part()
{
return new realpart;
}
}
// app.cpp
#include <part.h>
#include <iostream>
#include <memory>
// Also link to inventory.lib
int main()
{
using namespace std;
using namespace inventory;
unique_ptr< part > p( create_part() );
cout << p->id() << endl;
}
|
| Listing 3 |
Listing 3 shows the changes required to make part an interface. Notice the simple factory function to create a new instance. This is required since the type that implements the part interface, realpart, is in effect private to the library. For brevity, the necessary plumbing to make part a complete interface type, such as handling or prohibiting copying, have been left out.
The public-facing interface for the library now hides all the implementation details from clients, such as data members and private or protected member functions. These are significant changes, because it means that realpart can change in any way, as long as it correctly implements the part interface, without requiring any recompilation on the part of clients.
The introduction of part as an interface is a necessary change to achieve the goal of being able to add a method to that interface, but it is not sufficient to achieve it. Adding a method to the interface still requires client code to recompile.
False hope
Listing 4 shows an update to the part interface - a new method has been added. Even though the client code doesn't use the new method, it must recompile against the new interface definition, and still needs to re-deploy at the same time as the new library is deployed.
// part.h
#pragma once
#include <string>
namespace inventory
{
class part
{
public:
virtual ~part();
virtual int id() const = 0;
virtual std::string name() const = 0;
};
part * create_part();
}
// part.cpp
#include "part.h"
namespace
{
class realpart : public inventory::part
{
public:
realpart();
int id() const;
std::string name() const;
private:
int num;
std::string namestr;
};
}
namespace inventory
{
part * create_part()
{
return new realpart;
}
}
// app.cpp
#include <iostream>
#include <memory>
#include <inventory.h>
// Also link to inventory.lib
int main()
{
using namespace std;
std::unique_ptr< inventory::part > p(
inventory::create_part() );
cout << p->number() << endl;
}
|
| Listing 4 |
Suppose for a moment that the new library were deployed, and client code remained as it was - using the old interface. The client code had compiled against a definition of part that had only one method, and the deployed library has a part type that has two methods.
Common - but wrong
It's a fairly common practice in, for example, COM to enhance an existing interface by adding a new method to the end.3
This technique works, but does result in undefined behaviour, due to the one definition rule. However, since COM is defined according to strict compilation rules, and uses IDL to precisely specify object layout, this can be passed-off as platform-specific behaviour -just taking advantage of the code generated by the right compiler. It is not considered good practice in any case; interfaces are supposed to be immutable.
However, COM is not C++ -at its most basic level it is C, and so therefore doesn't use the C++ virtual despatch mechanism.
Even so, adding methods to the end of the interface isn't the real problem.
The real problem is with the implementation class, realpart.
Out of order
Changing the methods in a pure abstract class in C++ doesn't cause much of a problem at runtime (which is the point in the lifecycle about which we're most concerned here) because at the end of the day, a C++ interface is largely a compile time animal; it's purpose has to do with type, something the runtime environment knows and cares little about.
In order to see the real problem here, we'll have to start looking at the assembly code. The following examples were compiled with the Microsoft C++ compiler from Visual Studio 2010 (version 16 of cl.exe).
class properties
{
public:
virtual int integer() const { return 0; }
virtual double floatingpoint() const {
return 0; }
};
int main()
{
properties p;
}
|
| Listing 5 |
Listing 5 shows a very simple polymorphic class, properties. It exposes two virtual functions, integer and floatingpoint. The fact that they're inlined is not relevant. Note, however, they are not pure virtual, so a "real" vtable is defined. This file is then compiled with the following command:
cl /EHs /FAs test.cpp
/EHs means use ordinary C++ exceptions only (synchronous exceptions). /FAs causes the compiler to generate an assembly file -test.asm - with inline-source included. The interesting entries can be found by searching for properties::'vftable (That's a back-tick character there).
The first such entry shows the general layout of the properties class, including RTTI descriptors. The second instance shows the layout of the virtual function table, and should look similar to Figure 1.
??_7properties@@6B@ DD FLAT:??_R4properties@@6B@ ; properties::'vftable'
DD FLAT:?integer@properties@@EBEHXZ
DD FLAT:?floatingpoint@properties@@EBENXZ
; Function compile flags: /Odtp
|
| Figure 1 |
This section shows the physical storage for the vtable - the order of entries in it.
class properties
{
public:
virtual int integer() const { return 0; }
virtual double floatingpoint() const {
return 0;
}
virtual void integer( int ){}
virtual void floatingpoint( double ){}
};
int main()
{
properties p;
}
|
| Listing 6 |
If the properties class is now changed to that shown in listing 6, with new method overloads for the same names, and recompiled with the same options, the result is as shown in Figure 2
??_7properties@@6B@ DD FLAT:??_R4properties@@6B@ ; properties::'vftable'
DD FLAT:?integer@properties@@EAEXH@Z
DD FLAT:?integer@properties@@EBEHXZ
DD FLAT:?floatingpoint@properties@@EAEXN@Z
DD FLAT:?floatingpoint@properties@@EBENXZ
; Function compile flags: /Odtp
|
| Figure 2 |
What's really interesting about this result is the order of entries in the vtable. Refer back to listing 6, and compare the order.
What has actually occurred is that functions with the same name are grouped together, even though the actual order of declaration split the functions by getter and setter behaviour. It should be obvious what this means for our proposed method of adding new functions to the bottom of an interface:
It won't work.
It is not safe to depend on the order of the vtable matching the order of declaration. It's therefore unsafe to use a new version of the library without recompiling against its declared classes. Without that recompilation, when the client code calls on a virtual function, the wrong entry in the vtable is invoked (in this example), ultimately calling the wrong function. The results of that are hard to guess. Depending on the vtable order for a particular compiler is, at best, non-portable.
The true path
As was previously mentioned, this means that turning the part type into an interface isn't sufficient, on its own, to achieve what we need, but it is a necessary step.
The solution hinges around an observation made earlier in this article: adding a new type to a library is easily handled - clients running against a new version have no knowledge of the new type, and so cannot be dependent on it.
Extending interfaces
The basic premise of this solution is that instead of adding methods to an interface which is part of a deployed library, the new methods are added to a new interface.
The key to this working is that the new interface inherits publicly from the existing one.
Listing 7 shows the basic interface, part, which introduces simple get properties called number and name, along with how the client code may use it.
// part.h
#pragma once
#include <string>
namespace inventory
{
class part
{
public:
virtual ~part();
virtual unsigned id() const = 0;
virtual const std::string &
name() const = 0;
};
part * create_part();
}
// app.cpp
#include <part.h>
#include <iostream>
#include <memory>
// Also link to inventory.lib
int main()
{
using namespace std;
using namespace inventory;
unique_ptr< part > p( create_part() );
cout << p->id() << endl;
cout << p->name() << endl;
}
|
| Listing 7 |
New requirements arise to have the properties' values set by the client.
Listing 8 introduces part_v2, which extends part to add setters for the properties. Note that the names are (deliberately) overloaded, and imported to part_v2 with using statements.4
// part.h
#pragma once
#include <string>
namespace inventory
{
class part
{
public:
virtual ~part();
virtual unsigned id() const = 0;
virtual const std::string &
name() const = 0;
};
class part_v2 : public part
{
public:
using part::id;
using part::name;
virtual void id( unsigned val ) = 0;
virtual void name(
const std::string & val ) = 0;
};
part * create_part();
}
// app.cpp
#include <part.h>
#include <iostream>
#include <memory>
// Also link to inventory.lib
int main()
{
using namespace std;
using namespace inventory;
unique_ptr< part_v2 > p(
dynamic_cast< part_v2* >( create_part() ) );
p->id( 100 );
p->name( "wingnut" );
cout << p->id() << endl;
cout << p->name() << endl;
}
|
| Listing 8 |
Existing clients (as shown in listing 7) have no need to recompile, since the object returned from the factory is still an ordinary part, which has not changed. New clients wishing to take advantage of the new functionality, such as in listing 8, must compile against the new library.
A wrong turn
The interface required to extend the original part type has been presented (as part_v2), but what of the implementation? The factory must have something to create, and clients must, ultimately, have a real implementing object to do real work.
Listing 9 shows how one might approach the problem. Since clients only ever use the interface, part, the details of the implementing class are irrelevant.
#include "part.h"
namespace
{
class realpart : public inventory::part_v2
{
public:
realpart();
unsigned id() const;
const std::string & name() const;
void id( unsigned val );
void name( const std::string & val );
private:
unsigned num;
std::string namestr;
};
}
namespace inventory
{
part * create_part()
{
return new realpart;
}
}
|
| Listing 9 |
This code, however, suffers the same problem as the examples in section 2; it is the vtable of the implementing class that causes the problem, not the interface at all.
As it happens, using the same compiler and flags as before, we can see that this approach actually works in practice. For brevity, the code for part, part_v2, plus both complete versions of realpart have been put in a single file.
Listing 10 shows two versions of the part interface, and two independent implementing classes. realpart_v2 represents the code from listing 9 - a complete implementation of the part_v2 interface.
#include <string>
class part
{
public:
virtual int id() const = 0;
virtual const std::string & name() const = 0;
};
class part_v2 : public part
{
public:
virtual void id( int val ) = 0;
virtual void name(
const std::string & val ) = 0;
};
class realpart : public part
{
public:
int id() const { return num; }
const std::string & name() const {
return namestr; }
private:
int num;
std::string namestr;
};
class realpart_v2 : public part_v2
{
public:
int id() const { return num; }
const std::string & name() const {
return namestr; }
void id( int val ) { }
void name( const std::string & val ) { }
private:
int num;
std::string namestr;
};
int main()
{
realpart r1;
realpart_v2 r2;
}
|
| Listing 10 |
Compiled with the Microsoft Visual Studio 2010 C++ compiler as before:
cl /EHs /FAs test.cpp
figure 3 shows the vtable layouts corresponding to realpart and realpart_v2. As you can see, the compiler has helpfully laid the realpart_v2 vtable out by ensuring that the derived interface, part_v2, appears entirely after the base interface part.
??_7realpart@@6B@ DD FLAT:??_R4realpart@@6B@ ; realpart::'vftable'
DD FLAT:?id@realpart@@UBEHXZ
DD FLAT:?name@realpart@@UBEABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@XZ
; Function compile flags: /Odtp
??_7realpart_v2@@6B@ DD FLAT:??_R4realpart_v2@@6B@ ; realpart_v2::'vftable'
DD FLAT:?id@realpart_v2@@UBEHXZ
DD FLAT:?name@realpart_v2@@UBEABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@XZ
DD FLAT:?id@realpart_v2@@UAEXH@Z
DD FLAT:?name@realpart_v2@@UAEXABV?$basic_string@DU?$char_traits@D@std@@V?$allocator@D@2@@std@@@Z
; Function compile flags: /Odtp
|
| Figure 3 |
This makes sense: realpart_v2 derives directly from part_v2, which derives from part. It would be easy at this point to consider the job done.
It's still not portable however. The code for realpart_v2 is still dependent upon the implementation specific behaviour of the compiler in laying out the vtable this way. A new version of the same compiler might choose to group the functions in a different way, again resulting in undefined behaviour unless client code recompiles.
Virtually done
As with splitting the interface in two so that new methods are added by creating a new interface, so the implementation is split in a similar fashion, and follows the same pattern.
The part class interface in listing 11 is identical to that in listing 8, showing the part_v2 interface deriving from part. The implementation of part_v2 in a new class, realpart_v2, which derives not only from part_v2, but from the original realpart concrete implementation of the part interface.
// part.h
#pragma once
#include <string>
namespace inventory
{
class part
{
public:
virtual ~part();
virtual unsigned id() const = 0;
virtual const std::string &
name() const = 0;
};
class part_v2 : public part
{
public:
using part::id;
using part::name;
virtual void id( unsigned val ) = 0;
virtual void name(
const std::string & val ) = 0;
};
part * create_part();
}
// part.cpp
#include "part.h"
namespace
{
class realpart : public inventory::part
{
public:
realpart();
unsigned id() const;
const std::string & name() const;
protected:
unsigned num;
std::string namestr;
};
class realpart_v2 : public inventory::part_v2,
public realpart
{
public:
using part::id;
using part::name;
void id( unsigned val );
void name( const std::string & val );
};
}
namespace inventory
{
part * create_part()
{
return new realpart_v2;
}
}
|
| Listing 11 |
The realpart_v2 class uses implementation inheritance to bring in the pure-virtual declarations and implementations of the part interface, and with using declarations brings those names into scope to allow them to be overloaded with the new, setter, functions. Finally, the factory function create_part is changed to return an instance of the new implementing class.
In order to achieve the required behaviour, the data members of realpart (the base class) have been made protected, since realpart_v2 inherits from realpart and requires access to those members. A (possibly) neater but more verbose way of achieving this would be to add protected data accessors to realpart. Since client code has no knowledge of either implementing type, protected data in this instance is not a great problem.
Much more of a problem is the fact that this code will not (or at least, should not) compile.
Ambiguity banishment
Figure 4 shows the problem in stark relief. The relationships between realpart, realpart_v2, part and part_v2 form the dreaded diamond of multiple inheritance nightmares. The difficulty in compiling comes from the ambiguity between the views of part as seen by realpart_v2: one via part_v2, and another via realpart.
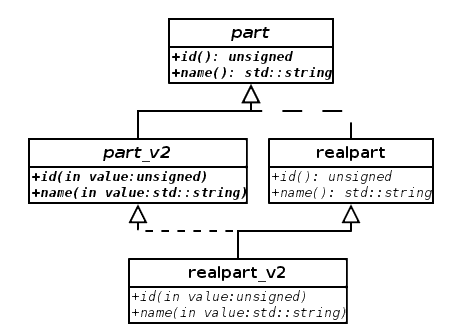 |
| Figure 4 |
The solution to this is to use virtual inheritance, a technique that should be infrequently required, but is essential in this instance.
Listing 12 shows the changes required.
// part.h
#pragma once
#include <string>
namespace inventory
{
class part
{
public:
virtual ~part();
virtual unsigned id() const = 0;
virtual const std::string & name() const
= 0;
};
class part_v2 : public virtual part
{
public:
using part::id;
using part::name;
virtual void id( unsigned val ) = 0;
virtual void name(
const std::string & val ) = 0;
};
part * create_part();
}
// part.cpp
#include "part.h"
namespace
{
class realpart : public virtual inventory::part
{
public:
realpart();
unsigned id() const;
const std::string & name() const;
protected:
unsigned num;
std::string namestr;
};
class realpart_v2
: public virtual inventory::part_v2,
public realpart
{
public:
using part::id;
using part::name;
void id( unsigned val );
void name( const std::string & val );
};
}
namespace inventory
{
part * create_part()
{
return new realpart_v2;
}
}
|
| Listing 12 |
part_v2 must virtually inherit from part, as must realpart. So, indeed, must realpart_v2, since it is intended as a base class for a (as yet non-existent) new extension, realpart_v3.
This is an ABI-breaking change in realpart, causing clients to recompile, because it changes the way the vtables are organised. In order to take advantage of the technique, it is necessary to plan for the future and ensure all classes derive virtually from the outset to avoid ambiguity.
Virtual inheritance is normally used to avoid ambiguity between the data members of a base class that appears twice in the inheritance family. The ambiguity here is caused not by data members, but by the necessity of overriding pure virtual functions. Without the virtual inheritance, realpart_v2 remains abstract, since it overrides only one set of part's functions, which are pure virtual. Virtual inheritance ensures that only one instance of the multiply-inherited base class appears in the derived class.
Finishing polish
With the technical problems solved, the necessary infrastructure is in place to achieve the primary goal of allowing the shared library to redeploy without requiring client code to also recompile and redeploy. However, there is more that can still be done to make the necessary client code easier to use.
Names have power
Note in listing 12 that the factory function, create_part, continues to return a part pointer. This cannot change to return a part_v2, because that would violate the one-definition rule, morally the same as changing a member function on an interface. Clients of the original library don't care, but clients of the new version (as in listing 8) must cast the result to the new version.
Ideally, clients should be able to use the result of the factory out of the box, confident that its type is the latest version, and that if the library is updated under their feet, so to speak, it will continue to work as before.
We can, in fact, go further than that.
It would be nice if the new version of the interface could be named the same as the old one. Then, clients who now require the new functionality don't need to find all the places they refer to part, and rename to part_v2.
We can go further still, and take the explicit responsibility for managing the lifetime of the returned object away from the client.
Called by a common name
Since the second version of the interface is part_v2, it makes sense to call the first one part_v1, and have something else which clients can refer to as part. An initial idea might be to make part a typedef of whatever the latest version of the part interface is, but even better than that, the goal of removing explicit management of lifetime away from the client can be met by making part a typedef to a smart pointer. Visual Studio 2010 comes with the right tool for this job as part of its C++0x (actually C++TR1) libraries.
#include "part_v1.h"
#include <memory>
namespace inventory
{
typedef part_v1 part_current;
typedef std::unique_ptr< part_current > part;
}
|
| Listing 13 |
Listing 13 shows a simple scheme to achieve this. The typedef part_current is used by the client to insulate it from the actual name of the latest interface version. When a new version of the part interface is added (e.g. part_v2), the part_current typedef also needs to change to reflect that.
Cast-free client
It has already been pointed out that the factory function used to instantiate a part cannot be modified to just return a pointer to whatever the current interface version is. Even using the typedef described above for this still results in a modified function when the typedef changes.
If clients are to be agnostic with regard to the actual version of the part interface, then it follows that there needs to be some intermediate place that can sensibly perform the right cast, and return the correct instance to the client.
This is crying out for a simple function template that just performs the right cast on the returned pointer from create_part().
namespace inventory
{
INVENTORY_LIB part_v1 * create_part_ptr();
template< typename type_version >
part create_part()
{
return part( dynamic_cast< type_version * >(
create_part_ptr() ) );
}
}
|
| Listing 14 |
Listing 14 shows how this can be done. The new create_part() function now calls into the renamed create_part_ptr() factory which performs the actual instantiation.
Making create_part a template neatly sidesteps the one-definition rule violation; a function specialised on a new version of the interface is a different function, and being a template, is compiled into the client, not the library. It does mean, however, that clients must still refer to the name of the interface's current version, and this is where the part_current typedef comes into play.
#include <part_factory.h>
#include <iostream>
int main()
{
using namespace std;
using namespace inventory;
part p = create_part< part_current >();
cout << p->number() << endl;
cout << p->name() << endl;
}
|
| Listing 15 |
Listing 15 shows how these two facilities are used by the client.
Dependency management
The final piece of the puzzle is how to organise the libraries so that the facilities are all available, without placing undue dependency strain on clients. The key to this is in the principle alluded to earlier - that abstractions should not depend upon details.
It's a prime-directive of our craft -separate interface from implementation - and to that end, the library will be split into two parts. One part contains only the interfaces necessary for clients to refer to objects. The second part, the implementation, also contains the necessary facilities to instantiate objects of the required interfaces.
This separation means that client code that has no need to create objects need depend only on the interfaces themselves.
Interface-only project
The main currency of the library here is the part type, which is actually an alias for a smart pointer to a specific version of an interface. It therefore makes sense that the definition of the name part exists in the context of the interface.
// part_v1.h
#include <string>
namespace inventory
{
class INVENTORY_LIB part_v1
{
public:
virtual ~part_v1();
virtual unsigned number() const = 0;
virtual const std::string & name()
const = 0;
};
}
// part.h
#pragma once
#include "part_v1.h"
#include <memory>
namespace inventory
{
typedef part_v1 part_current;
typedef std::unique_ptr< part_current > part;
}
|
| Listing 16 |
Listing 16 shows the contents of the library. This interface-only library is also the one that will be used by the most clients, and so should bear the name inventory. Client code need only include part.h, and ignore part_v1 as effectively implementation detail.
The real thing
The implementation of the interface, and the means to instantiate it, are the responsibility of the second library.
// realpart.h
#pragma once
#include <part_v1.h>
namespace inventory_impl
{
class realpart_v1 : public virtual inventory::part_v1
{
public:
realpart_v1();
virtual unsigned number() const;
virtual const std::string & name() const;
private:
unsigned num;
std::string namestr;
};
}
// part_factory.h
#include <part.h>
namespace inventory
{
INVENTORY_LIB part_v1 * create_part_ptr();
template< typename type_version >
part create_part()
{
return part( dynamic_cast< type_version * >( create_part_ptr() ) );
}
}
// part_factory.cpp
#include "realpart.h"
#include <part.h>
namespace inventory
{
using namespace inventory_impl;
INVENTORY_LIB part_v1 * create_part_ptr()
{
return new realpart_v1;
}
}
|
| Listing 17 |
Since it's expected to have fewer dependents than the interface library, the implementation library in listing 17 can have a less obvious name, e.g. inventory_impl. Note the virtual inheritance in listing 17; even though there is as yet no multiple inheritance occurring, the base must be derived virtually to avoid breaking changes when a new interface is added.
Version up!
When the time comes to add new functionality, four things are required (Listing 18):
// part_v2.h
#include "part_v1.h"
#include <string>
namespace inventory
{
class INVENTORY_LIB part_v2
: public virtual part_v1
{
public:
using part_v1::number;
using part_v1::name;
virtual void number( unsigned ) = 0;
virtual void name(
const std::string & ) = 0;
};
}
// part.h
#include "part_v2.h"
#include <memory>
namespace inventory
{
typedef part_v2 part_current;
typedef std::unique_ptr< part_current > part;
}
// realpart.h
#pragma once
#include <part_v2.h>
namespace inventory_impl
{
class realpart_v1
: public virtual inventory::part_v1
{
public:
realpart_v1();
virtual unsigned number() const;
virtual const std::string & name() const;
protected:
unsigned num;
std::string namestr;
};
class realpart_v2
: public virtual inventory::part_v2,
public realpart_v1
{
public:
using realpart_v1::id;
using realpart_v1::name;
virtual void number( unsigned );
virtual void name( const std::string & );
};
}
// part_factory.cpp
#include "realpart.h"
#include <part.h>
namespace inventory
{
using namespace inventory_impl;
INVENTORY_LIB part_v1 * create_part_ptr()
{
return new realpart_v2;
}
}
|
| Listing 18 |
- Add a new interface to the inventory project
- Update the part_current typedef
- Add a new class to implement the new interface
- Return an instance of the new implementing class from the factory
For brevity, the realpart_v1 and realpart_v2 code shares the same file.
At this point, the shared library can be released, and existing clients can upgrade at leisure. The reason this works is due to the code in listing 19.
#include <part.h>
namespace inventory
{
INVENTORY_LIB part_v1 * create_part_ptr();
template< typename type_version >
part create_part()
{
return part( dynamic_cast< type_version * >(
create_part_ptr() ) );
}
}
|
| Listing 19 |
The template function compiled into those clients would effectively be as follows:
part create_part()
{
return part( dynamic_cast< part_v1 * >(
create_part_ptr() ) );
}
Even though the new version of the library is returning an object which now derives from part_v2, those clients have no knowledge of that fact.
Clients who now compile against the new version of the library effectively compile against this:
part create_part()
{
return part( dynamic_cast< part_v2 * >(
create_part_ptr() ) );
}
And so can see the new functionality.
Justifying the means
As with many things technical and otherwise, this solution is a trade-off between convenience and effort. The convenience is provided by the fact that the shared library is backwards-compatible with clients who are already deployed, and does not require them to recompile and be re-released with a new library version.
This convenience comes at the expense of the effort requried to understand the interfaces in use, along with the fairly advanced techniques required to make it work portably. Instead of a single point of reference for all the facilities offered by an interface, the user must now follow a chain of base interfaces to determine how to use the whole. Similarly, following the chain of implementing classes is a definite obstacle to comprehending the code.
The use-case for which this code was originally developed was specifically focussed on the deployment dependencies between library and clients, in particular allowing clients of a previous version to continue unchanged when a new library was deployed. The cost of extra complexity in understanding the library was accepted as a necessary one to provide this feature. It is an idiom in common use, however, and understanding the idiom can help to reduce the complexity of understanding the solution.
The original requirement is all about loosening the coupling between client and library, achieved by judicious use of interfaces, then splitting the library into separate interface and implementation libraries. This separation allows clients to choose whether or not a dependency on the implementation -and the factory to create one -is required. If it is not needed, then the client can restrict their dependency to just the interface library. n
Acknowledgements
Many thanks to Roger Orr for identifying the real problem with extending interfaces by adding methods to the end. It was he who spotted that the vtable layout cannot be relied upon to match the declaration order, and who showed me how to find that information from the compiler. Thanks to Pete Goodliffe, Chris Oldwood and Frances Buontempo for providing valuable feedback on early drafts, and to all those who attended the presentation at Skills Matter in London, especially Sam Saariste, James Slaughter and Martin Waplington for making me think harder about it, and for pointing out some of the errors!
References
[Martin96] Robert C. Martin, 'The Dependency Inversion Principle', C++ Report, May 1996
1 For the purposes of this discussion, the language is C++ and the platform is Windows and DLLs. However, the principles described also apply to other platforms and languages to a greater or lesser degree. In any case, a stable and consistent ABI between clients and libraries is presumed.
2 Care must be taken with adding a new overload for an existing function, of course!
3 There are many caveats to this regarding changing UUIDs which are not really relevant to this article.
4 In reality, a new header file for part_v2 would be better than adding the new version to the end of the existing file.
Overload Journal #100 - December 2010 + Programming Topics
| Browse in : |
All
> Journals
> Overload
> o100
(7)
All > Topics > Programming (877) Any of these categories - All of these categories |