Journal Articles
| Browse in : |
All
> Journals
> Overload
> 92
(7)
All > Topics > Design (236) Any of these categories - All of these categories |
Note: when you create a new publication type, the articles module will automatically use the templates user-display-[publicationtype].xt and user-summary-[publicationtype].xt. If those templates do not exist when you try to preview or display a new article, you'll get this warning :-) Please place your own templates in themes/yourtheme/modules/articles . The templates will get the extension .xt there.
Title: The Generation, Management and Handling of Errors (Part 1)
Author:
Date: 09 August 2009 09:55:00 +01:00 or Sun, 09 August 2009 09:55:00 +01:00
Summary: An error handling strategy is important for robustness. Andy Longshore and Eoin Woods present a pattern language.
Body:
In recent years there has been a wider recognition that there are many different stakeholders for a software project. Traditionally, most emphasis has been given to the end user community and their needs and requirements. Somewhere further down the list is the business sponsor; and trailing well down the list are the people who are tasked with deploying, managing, maintaining and evolving the system. This is a shame, since unsuccessful deployment or an unmaintainable system will result in ultimate failure just as certainly as if the system did not meet the functional requirements of the users.
One of the key requirements for any group required to maintain a system is the ability to detect errors when they occur and to obtain sufficient information to diagnose and fix the underlying problems from which those errors spring. If incorrect or inappropriate error information is generated from a system it becomes difficult to maintain. Too much error information is just as much of a problem as too little. Although most modern development environments are well provisioned with mechanisms to indicate and log the occurrence of errors (such as exceptions and logging APIs), such tools must be used with consistency and discipline in order to build a maintainable application. Inconsistent error handling can lead to many problems in a system such as duplicated code, overly-complex algorithms, error logs that are too large to be useful, the absence of error logs and confusion over the meaning of errors. The incorrect handling of errors can also spill over to reduce the usability of the system as unhandled errors presented to the end user can cause confusion and will give the system a reputation for being faulty or unreliable. All of these problems are manifest in software systems targeted at a single machine. For distributed systems, these issues are magnified.
This paper sets out a collection (or possibly a language) of patterns that relate to the use of error generating, handling and logging mechanisms - particularly in distributed systems. These patterns are not about the creation of an error handling mechanism such as [Harrison] or a set of language specific idioms such as [Haase] but rather in the application code that makes use of such underlying functionality. The intention is that these patterns combine to provide a landscape in which sensible and consistent decisions can be made about when to raise errors, what types of error to raise, how to approach error handling and when and where to log errors.
Overview
The patterns presented in this paper form a pattern collection to guide error handling in multi-tier distributed information systems. Such systems present a variety of challenges with respect to error handling, including the distribution of elements across nodes, the use of different technology platforms in different tiers, a wide variety of possible error conditions and an end-user community that must be shielded from the technical details of errors that are not related to their use of the system. In this context, a software designer must make some key decisions about how errors are generated, handled and managed in their system. The patterns in this paper are intended to help with these system-wide decisions such as whether to handle domain errors (errors in business logic) and technical errors (platform or programming errors) in different ways. This type of far-reaching design decision needs careful thought and the intent of the patterns is to assist in making such decisions.
As mentioned above, the patterns presented here are not detailed design solutions for an error handling framework, but rather, are a set of design principles that a software designer can use to help to ensure that their error handling approach is coherent and consistent across their system. This approach to pattern definition means that the principles should be applicable to a wide variety of information systems, irrespective of their implementation technology. We are convinced of the applicability of these patterns in their defined domain. You may also find that they are applicable to systems in other domains - if so then please let us know.
The patterns in the collection are illustrated in Figure 1.
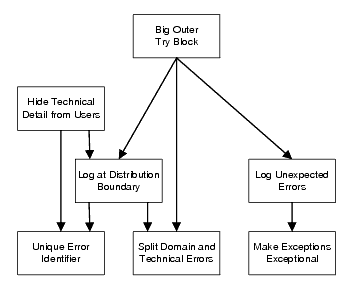 |
| Figure 1 |
The boxes in the diagram each represent a pattern in the collection. The arrows indicate dependencies between the patterns, with the arrow running from a pattern to another pattern that it is dependent upon. For example, to implement Log Unexpected Errors you must first Make Exceptions Exceptional. In turn, the Logging of Unexpected Errors supports a Big Outer Try Block. You can see that to get the most benefit from the set of patterns it is best to use the whole set in concert.
At the end of the paper, a set of proto-patterns is briefly described. These are considered to be important concepts that may or may not become fully fledged patterns as the paper evolves.
| Expected vs. unexpected and domain vs. technical errors | |||||||||
This pattern language classifies errors as 'domain' or 'technical' and also as 'expected' and 'unexpected'. To a large degree the relationship between these classifications is orthogonal. You can have an expected domain error (no funds in the account), an unexpected domain error (account not in database), an expected technical error (WAN link down - retry), and an unexpected technical error (missing link library). Having said this, the most common combinations are expected domain errors and unexpected technical errors. A set of domain error conditions should be defined as part of the logical application model. These form your expected domain errors. Unexpected domain errors should generally only occur due to incorrect processing or mis-configuration of the application. The sheer number of potential technical errors means that there will be a sizeable number that are unexpected. However, some technical errors will be identified as potentially recoverable as the system is developed and so specific error handling code may be introduced for them. If there is no recovery strategy for a particular error it may as well join the ranks of unexpected errors to avoid confusion in the support department ('why do they catch this and then re-throw it...'). The table below illustrates the relationship between these two dimensions of error classification and the recommended strategy for handling each combination of the two dimensions, based on the strategies contained in this collection of patterns.
|
Split Domain And Technical Errors
Problem
Applications have to deal with a variety of errors during execution. Some of these errors, that we term 'domain errors', are due to errors in the business logic or business processing (e.g. wrong type of customer for insurance policy). Other errors, that we term 'technical errors', are caused by problems in the underlying platform (e.g. could not connect to database) or by unexpected faults (e.g. divide by zero). These different types of error occur in many parts of the system for a variety of reasons. Most technical errors are, by their very nature, difficult to predict, yet if a technical error could possibly occur during a method call then the calling code must handle it in some way.
Handling technical errors in domain code makes this code more obscure and difficult to maintain.
Context
Domain and technical errors form different 'areas of concern'. Technical errors 'rise up' from the infrastructure - either the (virtual) platform, e.g. database connection failed, or your own artifacts, e.g. distribution façades/proxies. Business errors arise when an attempt is made to perform an incorrect business action. This pattern could apply to any form of application but is particularly relevant for complex distributed applications as there is much more infrastructure to go wrong!
Forces
- If domain code handles technical errors as well as domain ones, it becomes unnecessarily complex and difficult to maintain.
- A technical error can cause domain processing to fail and the system should handle this scenario. However, it can be difficult (or impossible) to predict what types of technical errors will occur within any one piece of domain code.
- It is common practice to handle technical errors at a technical boundary (such as a remote boundary). However, such a boundary should be transparent to domain errors.
- For some technical errors, it may be worth taking certain actions such as retrying (e.g. retry a database connection). However, such an action may not make sense for a domain error (e.g. no funds) where the inputs remain the same.
- As part of the specification of a system component, all of the potential domain errors originating from a domain action should be predictable and testable. However, changes in implementation may vary the number and type of technical errors that may possibly arise from any particular action.
- Technical and domain errors are of interest to different system stakeholders and will be resolved by members of different stakeholder groups.
Solution
Split domain and technical error handling. Create separate exception/error hierarchies and handle at different points and in different ways as appropriate.
Implementation
Errors in the application should be categorized into domain errors (aka. business, application or logical errors) and technical errors. When you create your exception/error hierachy for your application, you should define your domain errors and a single error type to indicate a technical error, e.g. SystemException (see Figure 2). The definition and use of a single technical error type simplifies interfaces and prevents calling code needing to understand all of the things that can possibly go wrong in the underlying infrastructure. This is especially useful in environments that use checked exceptions (e.g. Java).
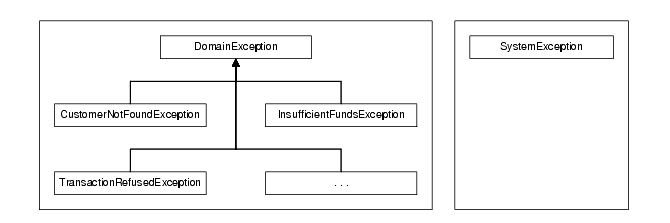 |
| Figure 2 |
Design and development policies should be defined for domain and technical error handling. These policies should include:
- A technical error should never cause a domain error to be generated (never the twain should meet). When a technical error must cause business processing to fail, it should be wrapped as a SystemError.
- Domain errors should always start from a domain problem and be handled by domain code.
- Domain errors should pass 'seamlessly' through technical boundaries. It may be that such errors must be serialized and re-constituted for this to happen. Proxies and façades should take responsibility for doing this.
- Technical errors should be handled in particular points in the application, such as boundaries (see Log at Distribution Boundary).
- The amount of context information passed back with the error will depend on how useful this will be for subsequent diagnosis and handling (figuring out an alternative strategy). You need to question whether the stack trace from a remote machine is wholly useful to the processing of a domain error (although the code location of the error and variable values at that time may be useful).
As an example, consider the exception definitions in Listing 1.
public class DomainException extends Exception
{
...
}
Public class InsufficientFundsException
extends Exception
{
...
}
public class SystemException extends Exception
{
...
}
|
| Listing 1 |
A domain method skeleton could then look like Listing 2.
public float withdrawFunds(float amount)
throws InsufficientFundsException,
SystemException
{
try
{
// Domain code that could generate various
// errors both technical and domain
}
catch (DomainException ex)
{
throw ex;
}
catch (Exception ex)
{
throw new SystemException(ex);
}
}
|
| Listing 2 |
This method declares two exceptions: a domain error - lack of funds to withdraw - and a generic system error. However, there are many technical exceptions that could occur (connectivity, database, etc.). The implementation of this method passes domain exceptions straight through to the caller. However, any other error is converted to a generic SystemException that is used to wrap any other (non-domain) errors that occur. This means that the caller simply has to deal with the two checked exceptions rather than many possible technical errors.
Positive consequences
- The business error handling code will be in a completely different part of the code to the technical error handling and will employ different strategies for coping with errors.
- Business code needs only to handle any business errors that occur during its execution and can ignore technical errors making it easier to understand and more maintainable.
- Business error handling code can be clearer and more deterministic as it only needs to handle the subset of business errors defined in the contract of the business methods it calls.
- All potential technical errors can be handled in surrounding infrastructure (server-side skeleton, remote façade or main application) which can then decide if further business actions are possible.
- Different logging and auditing policies are easily applied due to the clear distinction of error types.
Negative consequences
- Two exception hierarchies need to be maintained and there may be situations where this is artificial or the right location for an exception is not immediately obvious.
- Domain errors need to be passed through infrastructure code - possibly by marshaling and unmarshaling them across the infrastructure boundary (typically a distribution boundary).
Related patterns
- Technical and domain errors should be treated differently at distribution boundaries as defined in Log at Distribution Boundary
- Unless they are handled elsewhere in the system, both technical and domain errors should be handled by a Big Outer Try Block
- It is common to apply the proto pattern Single Type for Technical Errors
- A more general form of this pattern is described in Exception Hierarchy [Renzel97]
- The use of a domain hierarchy in Java is also discussed in the Exception Hierarchy idiom in [Haase]
- The Homogenous Exception and Exception Wrapping Java idioms in [Haase] show how you might implement SystemException in Java.
Log At Distribution Boundary
Problem
The details of technical errors rarely make sense outside a particular, specialized, environment where specialists with appropriate knowledge can address them. Propagating technical errors between system tiers results in error details ending up in locations (such as end-user PCs) where they are difficult to access and in a context far removed from that of the original error.
Context
Multi-tier systems, particularly those that use a number of distinct technologies in different tiers.
Forces
- You could propagate all the error information back to original calling application where it could be logged by a Big Outer Try Block but the complete set of error information is bulky and may include platform-specific information.
- Technical error information needs to be made easily accessible to the technology specialists (such as operating system administrators and DBAs) who should be able to resolve the underlying problems.
- When administrators come to resolve problems that technical errors reveal, they will need to access the error logs used by other parts of the system infrastructure as well as using the information in the error logged by the application. In order to facilitate this, technical errors need to be recorded in a log that is easily accessible from the same place as the infrastructure's error logs.
- Each technology platform has its own formats and norms for error logging. In order to fit neatly into the technology environment, it is desirable that the new system uses an appropriate logging approach in each environment.
- To correctly diagnose technical errors that occur on a particular system, extra technical information is often required about the current runtime environment (such as number of database connections open) but adding the additional code needed to recover and record this information to the various layers of application code would make such code significantly more complex.
- The handling of errors should not impact the normal behaviour of the system unnecessarily. To reduce any impact it is desirable to avoid passing large quantities of error information around the system.
Solution
When technical errors occur, log them on the system where they occur passing a simpler generic SystemError back to the caller for reporting at the end-user interface. The generic error lets calling code know that there has been a problem so that they can handle it but reduces the amount of system-specific information that needs to be passed back through the distribution boundary.
Implementation
Implement a common error-handling library that enforces the system error handling policy in each tier of the application. The implementation in each tier should log errors in a form that technology administrators are used to in that environment (e.g. the OS log versus a text file).
The implementation of the library should include both:
- Interfaces to log technical and domain errors separately
- A generic SystemError class (or data structure) that can be used to pass summary information back to the caller.
The library routine that logs technical errors (e.g. technicalError()) should:
- log the error with all of its associated detail at the point where it is encountered;
- return a unique but human readable error instance ID (for example, based on the date such as "20040302.12" for the 12th error on 2nd March 2004); and
- capture runtime environment information in the routine that logs a technical error and add this to the error log (if appropriate).
Whenever a technical error occurs, the application infrastructure code that catches the error should call the technicalError routine to log the error on its behalf and then create a SystemError object containing a simple explanation of the failure and the unique error instance ID returned from technicalError. This error object should be then returned to the caller as shown in Listing 3.
...
public class AccountRemoteFacade
implements AccountRemote
{
SystemError error = null;
public SystemError withdrawFunds(float amount)
throws InsufficientFundsException,
RemoteException
{
try
{
// Domain code that could generate various
// errors both technical and domain
}
catch (DomainException ex)
{
throw ex;
}
catch (Exception ex)
{
String errorId = technicalError(ex);
error = new SystemError(ex.getMessage(),
errorId);
}
}
return error;
}
|
| Listing 3 |
If a technical error can be handled within a tier (including it being 'silently' ignored - see proto-pattern Ignore Irrelevant Errors - except that it is always logged) then the SystemError need not be propagated back to the caller and execution can continue.
Positive consequences
- Only a required subset of the technical error information is propagated back to the remote caller - just enough for them to work out what to do next (e.g. whether to retry).
- Technical error information is logged in the environment to which it pertains (e.g. a Windows 2000 server) and in which it can be understood and resolved.
- The technical error information is logged in a similar way to (and potentially in the same place as) other system and infrastructure error information. This may make it easier to identify the underlying cause (e.g. if there are lots of related security errors alongside the database access error).
- Using local error logging mechanisms makes the logs much easier for technology administrators to access using their normal tools.
- The logging mechanism for technical errors can decorate the error information with platform-specific information that may assist in the diagnosis of the error.
Negative consequences
- One error can cause multiple log entries on different machines in a distributed environment (see Unique Error Identifiers pattern).
- Using local error logging mechanisms means that the approach used in each tier of the system may be different.
Related patterns
- Implementing Split Domain and Technical Errors before Log at Distribution Boundary makes implementation simpler, as it allows the two types of error to be clearly differentiated and handled differently.
- Unique Error Identifiers are needed if you want to tie distributed errors into a System Overview [Dyson04] and to to mitigate the potential confusion arising from one error causing multiple log entries.
Unique Error Identifier
Problem
If an error on one tier in a distributed system causes knock-on errors on other tiers you get a distorted view of the number of errors in the system and their origin.
Context
Multi-tier systems, particularly those that use load balancing at different tiers to improve availability and scalability. Within such an environment you have already decided that as part of your error handling strategy you want to Log at Distribution Boundary.
Forces
- It is often possible to determine the sequence of knock-on errors across a distributed system just by correlating raw error information and timestamps but this takes a lot of skill in system forensics and usually a lot of time.
- The ability to route calls from a host on one tier to one of a set of load-balanced servers in another tier improves the availability and scalability characteristics but makes it very difficult to trace the path of a particular cross-tier call through the system.
- You can correlate error messages based on their timestamp but this relies on all server times being synchronized and does not help when two errors occur on servers in the same tier within a small time window (basically the time to make a distributed call between tiers).
- Similar timestamps help to associate errors on different tiers but if many errors occur in a short period it becomes far harder to definitively associate an original error with its knock-on errors.
Solution
Generate a Unique Error Identifier when the original error occurs and propagate this back to the caller. Always include the Unique Error Identifier with any error log information so that multiple log entries from the same cause can be associated and the underlying error can be correctly identified.
Known uses
The authors have observed this pattern in use within a number of successful enterprise systems. We do not know of any publicly accessible implementations of it (because most systems available for public inspection are single tier systems and so this pattern is not relevant to them).
Implementation
The two key tenets that underlie this pattern are the uniqueness of the error identifier and the consistency with which it is used in the logs. If either of these are implemented incorrectly then the desired consequences will not result.
The unique error identifier must be unique across all the hosts in the system. This rules out many pseudo-unique identifiers such as those guaranteed to be unique within a particular virtual platform instance (.NET Application Domain or Java Virtual Machine). The obvious solution is to use a platform-generated Universally Unique ID (UUID) or Globally Unique ID (GUID). As these utilize the unique network card number as part of the identifier then this guarantees uniqueness in space (across servers). The only issue is then uniqueness across time (if two errors occur very close in time) but the narrowness of the window (100ns) and the random seed used as part of the UUID/GUID should prevent such problems arising in most scenarios.
It is important to maintain the integrity of the identifier as it is passed between hosts. Problems may arise when passing a 128-bit value between systems and ensuring that the byte order is correctly interpreted. If you suspect that any such problems may arise then you should pass the identifier as a string to guarantee consistent representation.
The mechanism for passing the error identifier will depend on the transport between the systems. In an RPC system, you may pass it as a return value or an [out] parameter whereas in SOAP calls you could pass it back in the SOAP fault part of the response message.
In terms of ensuring that the unique identifier is included whenever an error is logged, the responsibility lies with the developers of the software used. If you do not control all of the software in your system you may need to provide appropriate error handling through a Decorator [Gamma95] or as part of a Broker [Buschmann96]. If you control the error framework you may be able to propagate the error identifier internally in a Context Object [Fowler].
Positive consequences
- The system administrators can use a unified view of the errors in the system keyed on the unique error identifier to determine which error is the underlying error and which other errors are knock-ons from this one. If the errors in each tier are logged on different hosts it may be necessary to retrieve and amalgamate multiple logs in a System Overview [Dyson04] before such correlation can take place.
- Correlating errors based on the unique error id rather than the hosts on which they occur gives a far clearer picture of error cause and effect across one or more tiers of load-balanced servers.
- Skewed system times on different servers can cause problems with error tracing. If an error occurs when host 1 calls host 2, host 2 will log the error and host 1 will log the failed call. If the system time on host 1 is ahead of host 2 by a few milliseconds, it could appear that the error on host 1 occurred before that on host 2 - hence obscuring the sequence of cause and effect. However, if they both have the same unique error identifier, the two errors are inextricably linked and so the time skew could be identified and allowed for in the forensic examination.
- If lots of errors are generated on the same set of hosts at around the same time it becomes possible to determine if a consistent pattern or patterns of error cascade is occurring.
Negative consequences
- The derivation of a unique error identifier may be relatively complex in some environments and this could be a barrier to the pattern's adoption in some situations.
- The implementation of this pattern implies logging each error a number of times, once in each tier. This additional logging activity means that overall, logs will grow more quickly than in systems that do not implement this approach. This means that the runtime and administration overhead of this additional logging will need to be absorbed in the design of the system.
Related patterns
- Log at Distribution Boundary needs errors to have a unique error id in order to correlate the distributed errors.
- You may or may not employ Centralized Error Logging [Renzel97] to help assimilate errors.
To be continued...
So far, so good. However this is only part of the story as there are still some fundamental principles to be applied such as determining what is and is not an error. The remaining patterns in this pattern collection (Big Outer Try Block, Hide Technical Error Detail from Users, Log Unexpected Errors and Make Exceptions Exceptional) will show how the error handling jigsaw can be completed. These patterns will be explored in the next issue.
References
[Buschmann96] Pattern-Oriented Software Architecture, John Wiley and Sons, 1996
[Dyson04] Architecting Enterprise Solutions: Patterns for High-Capability Internet-based Systems, Paul Dyson and Andy Longshaw, John Wiley and Sons, 2004
[Gamma95] Design Patterns, Addison Wesley, 1995.
[Haase] Java Idioms - Exception Handling, linked from http://hillside.net/patterns/EuroPLoP2002/papers.html.
[Harrison] Patterns for Logging Diagnostic Messages, Neil B. Harrison
[Renzel97] Error Handling for Business Information Systems, Eoin Woods, linked from http://hillside.net/patterns/onlinepatterncatalog.htm
Notes:
More fields may be available via dynamicdata ..