Journal Articles
| Browse in : |
All
> Journals
> CVu
> 154
(12)
All > Journal Columns > Professionalism (40) Any of these categories - All of these categories |
Note: when you create a new publication type, the articles module will automatically use the templates user-display-[publicationtype].xt and user-summary-[publicationtype].xt. If those templates do not exist when you try to preview or display a new article, you'll get this warning :-) Please place your own templates in themes/yourtheme/modules/articles . The templates will get the extension .xt there.
Title: Professionalism in Programming #21
Author:
Date: 06 August 2003 13:15:59 +01:00 or Wed, 06 August 2003 13:15:59 +01:00
Summary:
Software architecture
Body:

Ignorance transcends architecture (James Gaskin)
Go into a city. Stand in the middle of it. Look around. Unless you've picked a pretty unusual place you are surrounded by a large number of buildings of varying ages and styles of construction. Some fit in to their surroundings sympathetically. Others look totally out of place. Some are aesthetically pleasing and seem well proportioned. Some are downright ugly. Some will still be there in 100 years time. Many will not.
The architects that designed these buildings took a lot into consideration before they even put pen to paper. Then during the process of design they worked carefully and methodically to ensure the building was feasible to fabricate, and balanced all the contending forces; user requirements, construction methods, maintainability, aesthetics, and so on.
Software is not made of bricks and mortar, but the same sort of careful thought is required to ensure a system meets similar sets of requirements. We have been erecting buildings far longer than we've been writing software, and it shows. We're still learning about what makes good software architecture.
Not too long ago I started working on a project whose software was pretty much undocumented and had been allowed to develop wildly with no careful green-fingered gardener to prune and tend the borders. Naturally it had become a woolly mess. Time came when we needed to understand how it all really worked, and an architectural diagram of the system was drawn up. There were so many different components (many largely redundant), inappropriate interconnections, and different methods of communication, that the diagram was an intense jumble of tightly woven lines in many interpretive colours. Almost as if a spider had fallen into a few pots of poster paint, and then spun psychedelic webs across the office.
And then it struck me. We had all but drawn a map of the London Underground. Our system bore such a striking resemblance it was uncanny - it was practically incomprehensible to an outsider, with many routes to achieve the same end, and the plan was still a gross simplification of reality. This was the kind of system that would vex a travelling salesman.
The lack of architectural vision had clearly made its mark on the software. It was hard to work with and hard to understand, with bits of functionality strewn across completely random modules. It had got to the point where the only useful thing you could do with it was throw it away.
In software construction, as in building construction, the architecture really matters.
In this little foray into the world of software architecture, we'll take a look at what it really is, what it really isn't, what it's used for, and investigate some common architectural patterns.
Architecture is the art of how to waste space (Philip Johnson)
So is this just another term that stretches the "building" metaphor a little thinner? Maybe so, but it is a genuinely useful concept. Software architecture is sometimes known as high-level design; terms get mixed up, but the meaning is the same. Architecture is just a more evocative description of this concept.
As an architect prepares a blueprint for a building, so the architecture is a blueprint for the software system. However, whilst a building's blueprint is a rigorously detailed plan with all the important features included, our software architecture is a top-level definition, an overview of the system specifically avoiding too much detail. It's macro, not micro.
In this high-level view all implementation details are hidden, and we just see the essential internal structure of the software. The architecture identifies the key software modules (or components, or libraries, at this point call them what you like: blobs), and identifies which ones communicate with each other. The architecture helps to identify and determine the nature of all the important interfaces in the system and helps to clarify the correct roles and responsibilities of the various subsystems. This information allows us to reason about the system as a whole without understanding how every part will work.
The key is that this design should be simple. A few wellchosen modules and sensible communication paths are the aim. It also needs to be comprehensible, which often means visually represented. A picture speaks a thousand words, after all.
In this way, the architecture is a framework into which the real development fits. It allows further design work to proceed with our focus on the right parts, and provides an initial way to split up work between teams. It allows us to weigh up different implementation strategies, in the same way you'd plan a journey from your home to a holiday destination in a different continent.
Not only does the architecture give a picture of how the system is composed, it also shows how it should be extended over time. In a large team, programs develop more elegantly when there's a clear unified vision of how the software should be adapted, what should be put in each module, where later modules will fit in to place, etc.
Exactly what needs to be addressed by the overall architecture will differ from project to project. On the whole, the target platform is not all that important at this stage; it may be possible to implement the architecture on a number of different machines using different languages and technologies. However, for certain projects it may be important to specify particular hardware components, most likely for embedded designs. For a distributed system the number of machines/processors and the split of work between them may be an architectural issue. If it's really fundamental to the overall design the architecture may also describe specific algorithms or data structures, although these two are less likely. There is a trade-off, though. The more information that gets set in stone at the architectural level, the less room for manoeuvre there is at a later implementation stage.
In physical architecture we use a number of different drawings or views of the same building: one for the physical structure, one for the wiring, one for the plumbing, etc. Similarly we may develop different software views in the architectural process. Four views are commonly recognised:
-
conceptual view (or logical view), shows the major parts of the system and their interconnections,
-
implementation view, a view in terms of the real implementation modules, which may have to differ from the neat conceptual model,
-
process view, the dynamic structure in terms of tasks, processes, and communication, used if there's a high degree of concurrency involved,
-
deployment view, shows the allocation of tasks to physical nodes, in a distributed system.
These views may arise as development work progresses. The main result of the architectural process is the first view, and that's what we're concentrating on here.
The architecture is captured in a high level document called something imaginative like the Architecture Specification. This specification explains the structure and shows how it fulfills the system requirements, including important issues like performance requirements, and how acceptable fault tolerance will be achieved.
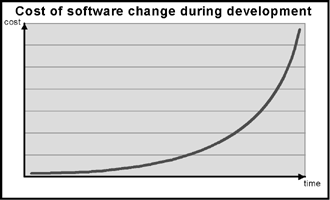 It is
therefore the first developmental step after the requirements have
been agreed upon. It's important that this is done up front because
it provides a first chance to validate design decisions that will
have the most significant impact on the project. It will expose
weaknesses and potential problems, saving a lot of time, effort and
money if a bad decision is reversed this early on. It's expensive
to change the foundation under a system when a lot of it has been
built. As the graph illustrates, the cost of a fixing a problem
escalates exponentially as you defer it[1].
It is
therefore the first developmental step after the requirements have
been agreed upon. It's important that this is done up front because
it provides a first chance to validate design decisions that will
have the most significant impact on the project. It will expose
weaknesses and potential problems, saving a lot of time, effort and
money if a bad decision is reversed this early on. It's expensive
to change the foundation under a system when a lot of it has been
built. As the graph illustrates, the cost of a fixing a problem
escalates exponentially as you defer it[1].
Certainly, architectural work is a form of design, but it is separate from the design phase, and distinct from low level design work, although it certainly overlaps somewhat. Later work on detailed design may feed changes back up to the system architecture. This is natural and healthy.
In a well-designed system there should be neither too few nor too many components. Of course what this means differs from project to project, get a sense of scale here. For a small program the architecture may fit on (or be done on) the back of an envelope, with just a few modules and some simple interconnections. A large system naturally requires more effort, and more paper.
With too many fine-grained components, the architecture is bewildering and hard to work with. It would imply that the architecture has gone into too much detail, and has become more of a general design. If there are too few components then you see far too much work being done by a single module. This makes the structure unclear, hard to maintain and hard to add to. The correct balance is in there somewhere.
The architecture should give as little information as possible about the inner workings of each module. The goal is that each module shouldn't have to know much about the other parts of the system. We aim for high cohesion and low coupling at this level of design, as with all others.
The architecture specification shows the set of design decisions made, and makes it clear why this approach is being favoured instead of the alternative strategies. It doesn't need to labour these other approaches, but must justify the chosen architecture and prove that some thought went into alternatives. It should have identified the primary goal of the architecture - for example modifiability is different from performance, and will lead to different architectural design decisions.
A good architecture leaves room for manoeuvre, it allows you to change your mind. For example it may specify that we wrap third party components with abstract interfaces so we can swap one version out for another. It may suggest technologies that make it easy to select different implementations during deployment.
The architecture must be clear and unambiguous. We should favour existing well-known architectural styles (see the later section for more on these), or should use known frameworks. It should be easy to understand and start working with.
A good architecture has a certain aesthetic appeal that makes it feel right.
Obviously, it's a key part of the system design. But the architecture has a number of uses that stretch a little further than this. We use the system architecture to:
-
Validate. As we've seen, the architecture is our first chance to validate what is going to be built. We can check that the system will meet all requirements. We can check that is really is feasible to build the system. We can ensure the design is internally consistent and hangs together well, with no special cases or gratuitous hacks. Nasty blemishes in the high-level design will only lead to more nefarious hacks at lower levels. The architecture helps to ensure we prevent any duplication of work, wasted effort, and redundancy. We use it to check there are no gaps in the strategy, that we have included all the necessary pieces. We ensure that there will be no mismatches as separate sections are brought together.
-
Communicate. We use the architecture specification to communicate the design to all interested parties. These may be system designers, implementers, maintainers, testers, customers, or managers. It's the primary route to understand the system, and as such an important piece of documentation should always be kept up to date as changes are made. Like any other piece of documentation, it can become dangerous as a lie.
The architecture conveys the vision of the system. It should identify how future extensions fit in neatly. It helps to maintain the "conceptual integrity" of the system, which Brooks speaks of [Brooks]. It implicitly provides a set of conventions, and contains an element of style. For example, it would be clear that you shouldn't introduce a custom socket connection for new component's communication if the rest of the design uses a CORBA infrastructure.
The architecture should naturally provide a route into the next level of design without being prescriptive.
-
Discriminate. We use the architecture to help us make decisions. For example, it identifies build vs buy decisions, identifies whether usage of a database is necessary, and clarifies the error handling strategy. It will flag problem areas, the areas of particular risk on the project, and help us plan to minimise this risk. Just as an architect's primary goal is to check his building stays up when it's built, under all expected conditions (and some unusual conditions too), so should our software structure produce a resilient product. A little wind or extra load shouldn't topple the thing over.
We need this system-wide perspective to make the appropriate tradeoffs ensuring the design meets its required properties. These important points are considered at the beginning rather than grafted in towards the end of development.
A good architecture captures information about each component, whatever component means in the architecture's context. It could be an object, a process, a library, a database, or a third party product. Each of the system's components will be a clear and logical unit. They each perform one task, and do it well. No component includes a kitchen sink, unless there's a specific kitchen sink module.
Whilst it won't dwell on a module's implementation issues, the architecture will describe any exposed facilities, and perhaps the important externally visible interfaces. It defines the visibility of the component, that is what it can see, what can see it, and what can't. Different architectural styles imply different visibility rules, as we'll see in the next section.
A connection may be a simple function call, or data flow through a pipe, it may be an event handler, or a message passing through some OS/network mechanism. A connection may be synchronous or asynchronous. Some collaborating components may have certain shared resources that they communicate indirectly through (for example, a subordinate component, a shared memory region, or something as basic as a file).
The architecture identifies all the inter-component connections, and describes all relevant connection properties. A property is relevant if it impacts how the system will operate.
Form ever follows function (Louis Henry Sullivan)
Just as an immense gothic cathedral and a quaint Victorian chapel, an imposing tower block and a 1970s public lavatory employ different architectural styles, there are a number of recognised software architectural styles that a system may be built upon. These styles are chosen for various reasons, good and bad, and differ in several ways. For example:
-
How resilient they are to changes in the data representation. In the worst case every component may need changing (e.g., a pipe and filters architecture). You might discover the need to change data representation when the input becomes too large to be held in memory at once.
-
How resilient they are to changes in algorithms.
-
How resilient they are to changes in functionality.
-
The method of separation/connection of the modules.
-
Their comprehensibility.
-
Their accommodation of performance requirements.
-
Any consideration of reusability of components.
In practice we may see a mixture of architectural styles in one system. Some data processing may progress through a pipe and filter process whilst the rest of the system's control is through component based design.
The following sections describe some common architectural styles. And compare them to pasta. Don't ask why.
 Like my
London Underground project, a system never has no architecture,
just no planned
architecture. Before long this state of affairs becomes an
albatross around the neck of your development team. The resultant
software will be a mess.
Like my
London Underground project, a system never has no architecture,
just no planned
architecture. Before long this state of affairs becomes an
albatross around the neck of your development team. The resultant
software will be a mess.
Architecture is a requirement of building good software. It is a part of the development process. Not planning an architecture is a sure fire way to doom yourself before you've even started.
This is probably the most commonly used architectural style in conceptual views. It describes the system as a hierarchy of layers, with a building block type approach. Sometimes the stacking bears more resemblance to reality than other times, but it is a very simple model to comprehend, and a non-techie can quickly grasp what it's telling them.
 Each
component is represented by a single block in the stack. The
positions in the stack indicate what lives where, how the
components relate to each other, and which components can 'see'
which other components. Blocks may be placed alongside each other
on the same level, and perhaps even can become tall enough to span
two layers. To illustrate how this works see the example layer
diagram, it shows a system close to my heart: trifle.
Each
component is represented by a single block in the stack. The
positions in the stack indicate what lives where, how the
components relate to each other, and which components can 'see'
which other components. Blocks may be placed alongside each other
on the same level, and perhaps even can become tall enough to span
two layers. To illustrate how this works see the example layer
diagram, it shows a system close to my heart: trifle.

A more serious (and famous) example of this is the OSI seven-layer reference model for network communication systems. In all honesty I've worked far more closely with the Goodliffe seven-layer trifle reference model, as has most of the civilised world.
At the lowest level in the stack we find the hardware interface, if our system does indeed interact with physical devices. Otherwise this level is reserved for the most basic service, perhaps the OS or a middleware technology like CORBA. The highest level will likely be occupied by the fancy interface that the user interacts with. As you get further up the stack of layers you move further away from the hardware, happily insulated by the layers in between, in the same way that the roof of a house doesn't have to worry about the magma at the earth's core.
At any point you should be able to brush out all the lower layers and slot in a new implementation of the layer below that honours the same set of interfaces - the system should function as before. This is a key point: it means that you can run the same C++ code on any computing platform that supports your C++ environment. You can swap the hardware platform without touching your application code - relying on the OS layer (for example) to swallow the technical differences for you. Handy.
Being at a higher level means that you can use the public interfaces of the layer directly below. Whether you can use the public interfaces of any lower levels depends of your definition of layering. Sometimes the diagram is fiddled to represent this, as in the sherry brick in the trifle stack. You certainly can't use anything from a higher level; if you break this edict you no longer have a layered architecture, just a pretty diagram drawn in stack form.
Whether components on the same layer can interconnect is again not rigidly defined, but up to the particular definition of layering you choose to adopt.
As you can see, most uses of layering are hardly formal. The relative size and position of boxes gives a clue as to importance of a component, and as an overview that is generally sufficient. The connections are implicit, and in this view the methods of communication irrelevant (however, this can be a key architectural concern for the efficiency of system - you don't send gigabytes of data down an RS232 serial port, after all).
 This
architecture is modelled after the logical flow of data through the
system. It is implemented as a string of sequential modules which
each read some data in, process it, and spit it out again.
Somewhere at the start of the chain is a data generator (maybe a
user interface, perhaps some hardware data harvesting logic), at
the end is a data sink (perhaps the computer display). It's Chinese
Whispers in digital form. The data flows down the pipe encountering
the various filters en route.
This
architecture is modelled after the logical flow of data through the
system. It is implemented as a string of sequential modules which
each read some data in, process it, and spit it out again.
Somewhere at the start of the chain is a data generator (maybe a
user interface, perhaps some hardware data harvesting logic), at
the end is a data sink (perhaps the computer display). It's Chinese
Whispers in digital form. The data flows down the pipe encountering
the various filters en route.
The transformations are usually incremental; each filter does a single simple process and tends to have very little internal state. This form is commonly seen in exotic Unix command line incantations, and the pipe and filter architecture is often implemented by this mechanism. If each filter stage requires all its input before spitting out any output, the architecture is essentially equivalent to a batch processing system.
The pipe and filter architecture requires a well defined structuring of data between each filter, and has the implicit overhead of repeatedly encoding the output data for transmission down the pipe and parsing back again in each subsequent filter. For this reason the data stream is usually very simple, just a plain ASCII format, otherwise the burden is too great.
This architecture can make it very easy to add functionality by just plugging in a new filter into the pipeline. However its great downside is error handling. It is hard to determine where an error originated in the pipeline by the time a problem manifests itself at the sink. It's cumbersome to pass error codes down chain towards output stage, it needs extra encoding and is hard work to handle uniformly in several separate code modules. The filters may use a separate error channel (e.g. stderr), but error messages can still easily get mixed up.
 This
architecture decentralises the control and splits it into a number
of separate collaborating components, rather than a single
monolithic structure. It is essentially an object-oriented
approach, but doesn't necessarily require implementation in an OO
language. Each component's public interface is defined in an
Interface Definition
Language (or IDL) which is separate from any
implementation.
This
architecture decentralises the control and splits it into a number
of separate collaborating components, rather than a single
monolithic structure. It is essentially an object-oriented
approach, but doesn't necessarily require implementation in an OO
language. Each component's public interface is defined in an
Interface Definition
Language (or IDL) which is separate from any
implementation.
Component based design arrived with the lure of assembling applications quickly out of prefabricated components, supposedly enabling plug-and-play solutions. It's still up for debate how much of a success this has been. Not all components are designed for reuse (it's hard work), and it's not always easy to find a component for what you want. It's easiest for UIs where popular frameworks and established marketplaces exist.
The core of a component based architecture is a component communication infrastructure, or middleware, which allows components to be plugged in easily, to broadcast their existence, and advertise the services they provide. Components are used by looking up this information through some middleware mechanism, rather than by hardwiring a direct connection between two components. Common middleware platforms include CORBA, JavaBeans and COM, each have different pros and cons.
So what is a component? That turns out to be a good question - not everyone agrees on the answer. A component is essentially an implementation unit. It honours one (maybe more) specific published IDL interfaces. This interface is how clients of the component interact with it. There are no back doors. The client is concerned with dealing with an instance of that interface, rather than in how the component is implemented.
Each component is an individual independent piece of code. Behind its interface it implements some logic (perhaps 'business logic' or user interface activity), and contains some data, which may just be local, or may be published (say a file store or database component). Components should not need to know much about each other. If they are tightly coupled then the architecture is just a badly designed monolithic system in disguise as a modern buzzword-compliant product.
The component based architecture may be deployed in a networked environment with components on different machines, but can as easily be a single machine installation. This may depend on the type of middleware in use.
 Instead of
developing a new architecture for a specific project it may be
appropriate to use an existing application framework and slot
development into that skeleton. A framework is an extensible
library of code (usually a set of co-operating classes) that forms
a reusable design solution for a particular problem domain. When
using a framework most of the effort has been done for you, with
the remaining pieces following a fill-in-the-blanks approach.
Different frameworks will follow different architectural models -
by using a framework you commit to its particular style.
Instead of
developing a new architecture for a specific project it may be
appropriate to use an existing application framework and slot
development into that skeleton. A framework is an extensible
library of code (usually a set of co-operating classes) that forms
a reusable design solution for a particular problem domain. When
using a framework most of the effort has been done for you, with
the remaining pieces following a fill-in-the-blanks approach.
Different frameworks will follow different architectural models -
by using a framework you commit to its particular style.
Frameworks differ from traditional libraries in the way they interact with your code. When using a library you make explicit calls into the library components under your own thread of control. A framework turns this around; it is itself responsible for the structure and flow of control. It will call into your supplied code as and when necessary.
Most of the popular frameworks available are for the user interface domain.
Alongside the use of off-the-shelf frameworks is the consideration of design patterns. Whilst not an architectural style in their own right, patterns are small-scale architectural templates. Usually employed at the design level rather than in the system architecture, they are micro-architectures for a few collaborating components, distilling a recurring structure of communication. A design pattern solves a general design problem within a particular context. Patterns are a set of design best practices, and are described in the ubiquitous GoF book [Gamma-et-al] and numerous subsequent publications.
The Roman architect Vitruvius made a timeless statement of what constituted good design: strength (firmitas), utility (utilitas), and beauty (venustas) [Pollio]. This holds true for our software architectures. Without a well-defined, well communicated architecture, a software project will lack a cohesive internal structure. It will become brittle, unstable and ugly. Eventually it will reach a breaking point.
All this talk of pasta has made me hungry. I'm off to build a seven-layer reference trifle.
[Brooks] Frederick P. Brooks, Jr. The Mythical Man-Month, Anniversary Edition. Addison Wesley, 1995. ISBN: 0-201-83595-9.
Notes:
More fields may be available via dynamicdata ..